preview_ready
Your preview summary will appear here after generation.
Language suggestion
Scanned PDF to EPUB, without the blind leap
Upload one scanned PDF, preview the first 10 pages as EPUB, and check OCR, line breaks, and reading order before you commit to a full conversion.
Drop one scanned PDF, preview the first 10 pages as EPUB, and stop early if OCR or layout problems make the file a bad conversion candidate.
Try the demo
This preview flow packages only the first 10 pages. If headings, line breaks, or OCR still look broken, you can stop here before a bigger conversion job.
Choose a PDF above, then generate the preview EPUB.
Progress
Waiting to upload
Preview Status
Processing
Upload a PDF above to start the preview flow.
Preview pages
0
OCR used
0
Needs review
0
preview_ready
Your preview summary will appear here after generation.
Inline preview
Inspect the first few preview pages here, then download the EPUB if the reading quality looks good.
Most users should start with the PDF upload above. Open this only when you need to inspect extracted text line by line before conversion.
Use this only when you want to inspect a single extracted page by hand. The main product path is still the PDF upload above.
Overall score
55/100
Issues found
3
Needs review
2
Critical
0
Broken hyphenation
Broken hyphenation detected.
Formula structure risk
Formula-like text detected; check rendering strategy.
Page number leak
Last line looks like a page number.
Direct answer
A PDF to EPUB converter with OCR turns an image-based or scanned PDF book into a reflowable EPUB. Scanned PDF to EPUB keeps the main PDF-to-EPUB job preview-first: upload one PDF, generate an EPUB preview from the first 10 pages, then check OCR and layout risk before a full-book conversion.
The current product is not a full publishing pipeline. It answers one question first: can this scanned PDF become a readable EPUB without wasting more time?
1
Choose one scanned PDF and generate a short EPUB preview from the first pages.
2
Open the preview and check whether line breaks, headings, formulas, and captions still feel readable.
3
Continue to full conversion, repair the source, or stop before you sink more effort into a bad scan.
What readers keep running into
Across Reddit, Calibre threads, and e-reader forums, scanned-book readers repeat the same frustrations. The preview exists to answer them before you commit to a full run.
01
Many scanned PDFs are just page photos. Without a usable text layer, converters stall, inflate file size, or embed each page as an image.
02
Hidden OCR layers often contain broken hyphenation, wrong quotes, stray symbols, and line endings that look fine in search but fail in reflowed reading.
03
Scientific papers and old journals lose reading order fast. Multi-column layouts, display math, and figure captions are where trust usually breaks.
04
Even when a PDF opens, small-screen reading often becomes zoom, pan, crop, repeat. Users want to know whether reflow will actually feel readable before they invest hours.
Popular workflows
These short pages match the common search intents behind the same upload flow: preview, OCR repair, line breaks, table of contents, footnotes, Kindle, Kobo, two-column PDFs, and private upload decisions.
These examples do the job the copy cannot: show what different scanned PDFs look like before conversion, and what a believable EPUB preview needs to preserve on the other side.

Use Case 1
This is the simplest but highest-volume use case: judge whether a yellowed chapter scan becomes comfortable enough to read on a small e-reader.

Use Case 2
Formula pages break trust fast. A useful preview proves that equations, theorem blocks, and surrounding explanation still make sense on a real reading device.
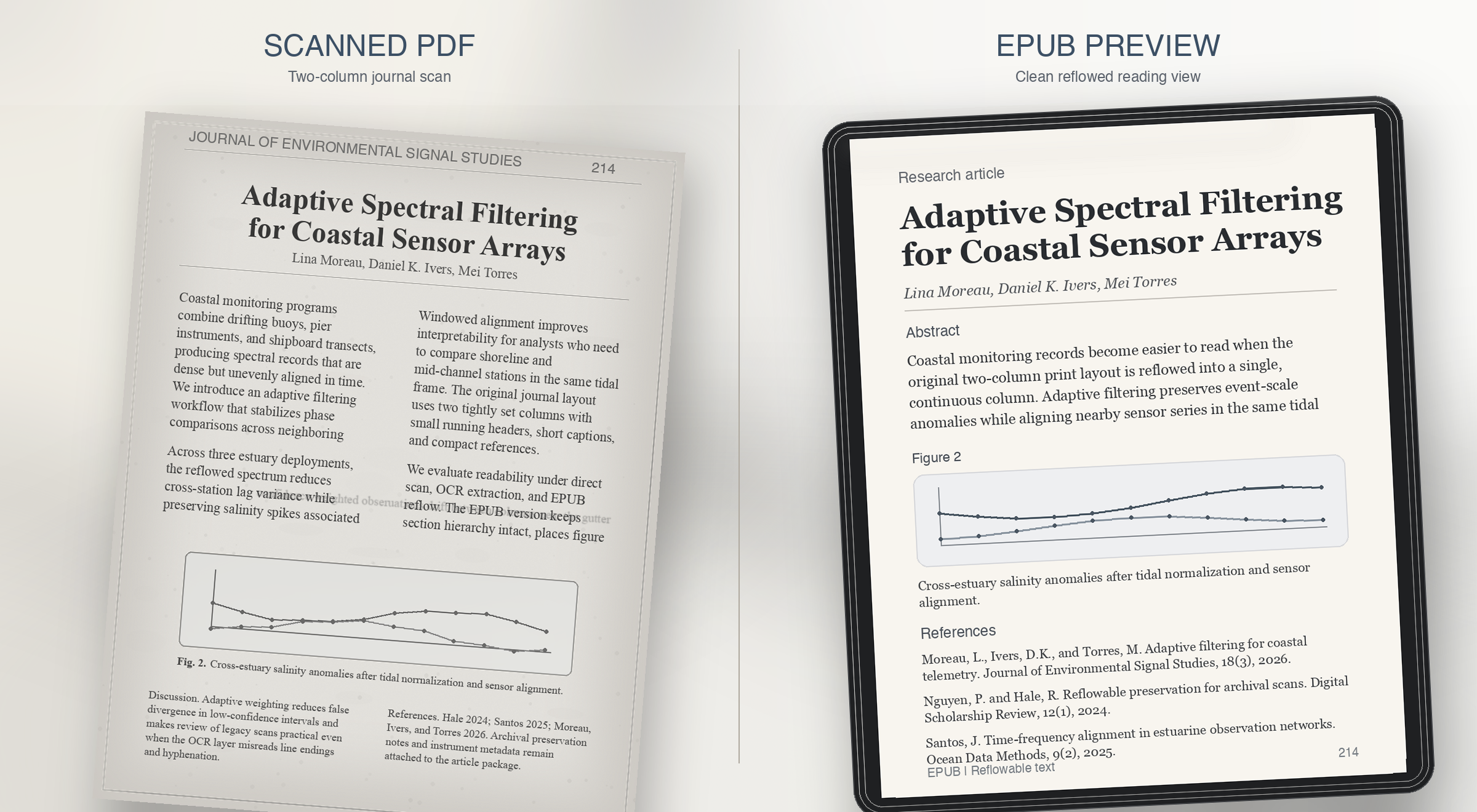
Use Case 3
Research journals usually fail on reading order. The preview should prove that columns, captions, and references survive reflow instead of collapsing together.

Use Case 4
Some PDFs have no usable text layer at all. The right behavior is not fake confidence, but a preview that shows what OCR recovered and what still needs review.
Simple pricing
Use the free preview to check OCR, reading order, and page-number leaks. Pro is for testing more PDFs. Done-for-you Repair is for files that need a human cleanup pass.
Free
$0 preview trial
Pro
$19 per month
Done-for-you Repair
from $199 per PDF
Pro checkout runs through Stripe after one-time email sign-in. If checkout is temporarily unavailable, the Pro button falls back to email. Repair work is still quoted from the preview report before delivery.
The live checker runs the repo's quality rules against extracted page text. It flags empty OCR output, page-number leaks, broken hyphenation, bad spacing, and formula-structure risk.
The current demo can generate a preview EPUB directly from an uploaded PDF. Production-grade full-book conversion still needs stronger layout recovery, better OCR repair, EPUB validation, and job orchestration.
In this demo, the PDF is uploaded to the current preview service so it can generate a sample EPUB. Review your deployment and privacy settings before testing private material. The page checker still exists for users who want to inspect extracted text before uploading.
The wedge is scanned PDF input, extracted page text for diagnosis, and a reflowable EPUB preview for reading on Kindle- and Kobo-style devices. It is not trying to become a broad everything-to-everything converter.
Accurate enough to judge reading comfort and obvious structural damage. The preview is meant to answer whether the book feels clean enough to continue, not to replace final editorial review for every edge case.
Some cleanup can be automated, but the product should stay honest about uncertainty. The key promise is to surface where review is needed so the user can decide whether to repair, crop, rerun OCR, or stop.
Those are the pages most likely to trigger risk labels. Formula structure, tabular alignment, footnotes, and badly cropped scans often need targeted repair before an EPUB is truly comfortable to read.
Readers and document owners with scanned books, academic PDFs, or public-domain material who want a reflowable EPUB for Kindle or Kobo without proofreading every page manually.
Generic converters export files, but they rarely explain where OCR or layout recovery failed. This product is designed to show risk before the user commits to a full conversion.
Yes. The main demo flow is designed around that exact question: upload one PDF, inspect the first pages, review OCR risk, and judge whether the full book is worth converting.
The most useful examples are before-and-after comparisons for noisy OCR, math-heavy academic pages, two-column journal layouts, footnotes, captions, and image-only scans that need OCR fallback.
It should prove reading comfort, not just file export. A good preview shows whether line breaks, page numbers, formulas, headings, columns, and captions still make sense on a small reading device.
Get OCR repair notes, EPUB preview releases, and full-book conversion availability.