apercu_pret
Le résumé de votre aperçu apparaîtra ici une fois prêt.
Suggestion de langue
PDF scanné vers EPUB, sans conversion à l'aveugle
Importez un PDF scanné, générez un véritable aperçu EPUB des 10 premières pages, puis décidez si le fichier mérite une conversion complète avant d'y consacrer plus de temps.
Déposez un PDF scanné, prévisualisez les 10 premières pages en EPUB, et arrêtez-vous tôt si le scan ne mérite pas une conversion complète.
Essayer la démo
Cette démo locale n'emballe que les 10 premières pages. Si les titres, les sauts de ligne ou les formules restent cassés, vous pouvez arrêter ici avant un travail plus lourd.
Choisissez un PDF ci-dessus, puis générez l'aperçu EPUB.
Progression
En attente d'envoi
État de l'aperçu
Traitement
Importez un PDF ci-dessus pour démarrer l'aperçu.
Pages d'aperçu
0
Pages OCR
0
À revoir
0
apercu_pret
Le résumé de votre aperçu apparaîtra ici une fois prêt.
Apercu dans la page
Consultez ici les premieres pages de l'aperçu, puis telechargez l'EPUB si la lecture vous convient.
La plupart des utilisateurs doivent commencer par l'import PDF. Ouvrez ceci uniquement si vous devez vérifier le texte extrait ligne par ligne avant conversion.
Utilisez ceci uniquement si vous voulez inspecter à la main une seule page extraite. Le chemin principal reste l'import PDF ci-dessus.
Score global
55/100
Problèmes détectés
3
À revoir
2
Critique
0
Césure cassée
Une césure cassée a ete detectee.
Risque sur la structure de formule
Du texte ressemblant a une formule a ete detecte ; verifiez la strategie de rendu.
Fuite de numero de page
La derniere ligne ressemble a un numero de page.
Direct answer
A PDF to EPUB converter with OCR turns an image-based or scanned PDF book into a reflowable EPUB. Scanned PDF to EPUB keeps the main PDF-to-EPUB job preview-first: upload one PDF, generate an EPUB preview from the first 10 pages, then check OCR and layout risk before a full-book conversion.
Le produit actuel n'est pas une chaîne d'édition complète. Il répond d'abord à une question : ce PDF scanné peut-il devenir un EPUB lisible sans perdre plus de temps ?
1
Choisissez un PDF scanné et générez un court aperçu EPUB depuis les premières pages.
2
Ouvrez l'aperçu et vérifiez si les sauts de ligne, titres, formules et légendes restent lisibles.
3
Poursuivez la conversion complète, réparez la source, ou arrêtez-vous avant de gaspiller plus d'effort sur un mauvais scan.
Ce que les lecteurs rencontrent sans cesse
Sur Reddit, dans les fils Calibre et sur les forums d'e-readers, les lecteurs de livres scannés répètent les mêmes frustrations. L'aperçu existe pour y répondre avant une conversion complète.
01
Beaucoup de PDF scannés ne sont que des photos de pages. Sans calque texte utile, les convertisseurs bloquent, gonflent la taille du fichier ou embarquent chaque page en image.
02
Les calques OCR cachés contiennent souvent des césures cassées, de mauvaises guillemets, des symboles parasites et des retours à la ligne qui passent en recherche mais cassent en reflow.
03
Les articles scientifiques et les anciennes revues perdent vite leur ordre de lecture. Les colonnes, les formules affichées et les légendes sont l'endroit où la confiance se brise.
04
Même quand le PDF s'ouvre, la lecture sur petit écran devient souvent zoom, déplacement, recadrage, répétition. L'utilisateur veut savoir si le reflow sera réellement lisible.
Ces exemples font ce que le texte ne peut pas faire : montrer à quoi ressemblent différents PDF scannés avant conversion, et ce qu'un aperçu EPUB crédible doit préserver.

Use Case 1
This is the simplest but highest-volume use case: judge whether a yellowed chapter scan becomes comfortable enough to read on a small e-reader.

Use Case 2
Formula pages break trust fast. A useful preview proves that equations, theorem blocks, and surrounding explanation still make sense on a real reading device.
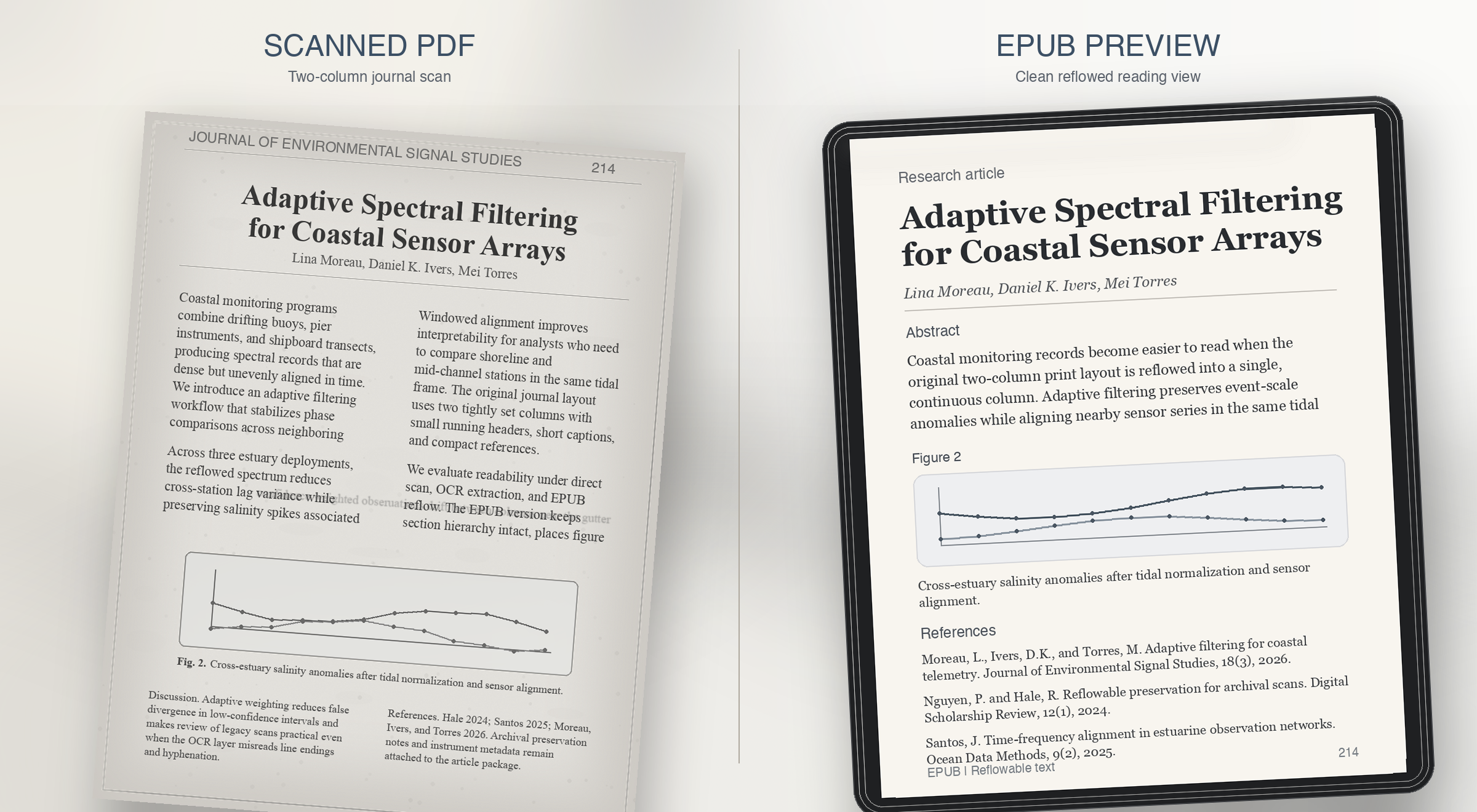
Use Case 3
Research journals usually fail on reading order. The preview should prove that columns, captions, and references survive reflow instead of collapsing together.

Use Case 4
Some PDFs have no usable text layer at all. The right behavior is not fake confidence, but a preview that shows what OCR recovered and what still needs review.
Simple pricing
Use the free preview to check OCR, reading order, and page-number leaks. Pro is for testing more PDFs. Done-for-you Repair is for files that need a human cleanup pass.
Free
$0 preview trial
Pro
$19 per month
Done-for-you Repair
from $199 per PDF
Pro checkout runs through Stripe after one-time email sign-in. If checkout is temporarily unavailable, the Pro button falls back to email. Repair work is still quoted from the preview report before delivery.
The live checker runs the repo's quality rules against extracted page text. It flags empty OCR output, page-number leaks, broken hyphenation, bad spacing, and formula-structure risk.
The current demo can generate a preview EPUB directly from an uploaded PDF. Production-grade full-book conversion still needs stronger layout recovery, better OCR repair, EPUB validation, and job orchestration.
In this demo, the PDF is uploaded to the current preview service so it can generate a sample EPUB. Review your deployment and privacy settings before testing private material. The page checker still exists for users who want to inspect extracted text before uploading.
The wedge is scanned PDF input, extracted page text for diagnosis, and a reflowable EPUB preview for reading on Kindle- and Kobo-style devices. It is not trying to become a broad everything-to-everything converter.
Accurate enough to judge reading comfort and obvious structural damage. The preview is meant to answer whether the book feels clean enough to continue, not to replace final editorial review for every edge case.
Some cleanup can be automated, but the product should stay honest about uncertainty. The key promise is to surface where review is needed so the user can decide whether to repair, crop, rerun OCR, or stop.
Those are the pages most likely to trigger risk labels. Formula structure, tabular alignment, footnotes, and badly cropped scans often need targeted repair before an EPUB is truly comfortable to read.
Readers and document owners with scanned books, academic PDFs, or public-domain material who want a reflowable EPUB for Kindle or Kobo without proofreading every page manually.
Generic converters export files, but they rarely explain where OCR or layout recovery failed. This product is designed to show risk before the user commits to a full conversion.
Yes. The main demo flow is designed around that exact question: upload one PDF, inspect the first pages, review OCR risk, and judge whether the full book is worth converting.
The most useful examples are before-and-after comparisons for noisy OCR, math-heavy academic pages, two-column journal layouts, footnotes, captions, and image-only scans that need OCR fallback.
It should prove reading comfort, not just file export. A good preview shows whether line breaks, page numbers, formulas, headings, columns, and captions still make sense on a small reading device.
Recevez les notes OCR, les aperçus EPUB et la disponibilité de la conversion complète.