vorschau_bereit
Deine Vorschau-Zusammenfassung erscheint hier nach der Generierung.
Sprachvorschlag
Gescanntes PDF zu EPUB, ohne Blindflug
Lade ein gescanntes PDF hoch, erzeuge eine echte EPUB-Vorschau der ersten 10 Seiten und entscheide dann, ob sich eine Vollkonvertierung lohnt, bevor du mehr Zeit investierst.
Lege ein gescanntes PDF ab, prüfe die ersten 10 Seiten als EPUB und stoppe früh, wenn sich der Scan nicht für eine Vollkonvertierung lohnt.
Demo testen
Diese lokale Demo verpackt nur die ersten 10 Seiten. Wenn Überschriften, Zeilenumbrüche oder Formeln noch kaputt aussehen, kannst du hier vor einem größeren Job stoppen.
Wähle oben ein PDF und erzeuge dann die Vorschau-EPUB.
Fortschritt
Warten auf Upload
Vorschaustatus
Verarbeitung
Lade oben ein PDF hoch, um die Vorschau zu starten.
Vorschauseiten
0
OCR-Seiten
0
Prüfen
0
vorschau_bereit
Deine Vorschau-Zusammenfassung erscheint hier nach der Generierung.
Vorschau auf der Seite
Prufe hier die ersten Vorschauseiten und lade danach das EPUB herunter, wenn sich das Lesen gut anfuhlt.
Die meisten Nutzer sollten mit dem PDF-Upload oben beginnen. Öffne dies nur, wenn du den extrahierten Text vor der Konvertierung Zeile für Zeile prüfen musst.
Nutze dies nur, wenn du eine einzelne extrahierte Seite manuell prüfen willst. Der Hauptpfad bleibt der PDF-Upload oben.
Gesamtwert
55/100
Gefundene Probleme
3
Zu prüfen
2
Kritisch
0
Fehlerhafte Trennung
Fehlerhafte Trennung erkannt.
Risiko bei Formelstruktur
Formelähnlicher Text erkannt; prüfe die Renderstrategie.
Seitenzahl-Leck
Die letzte Zeile sieht wie eine Seitenzahl aus.
Direct answer
A PDF to EPUB converter with OCR turns an image-based or scanned PDF book into a reflowable EPUB. Scanned PDF to EPUB keeps the main PDF-to-EPUB job preview-first: upload one PDF, generate an EPUB preview from the first 10 pages, then check OCR and layout risk before a full-book conversion.
Das aktuelle Produkt ist keine vollständige Publishing-Pipeline. Es beantwortet zuerst eine Frage: Kann dieses gescannte PDF zu einem lesbaren EPUB werden, ohne mehr Zeit zu verschwenden?
1
Wähle ein gescanntes PDF und erzeuge aus den ersten Seiten eine kurze EPUB-Vorschau.
2
Öffne die Vorschau und prüfe, ob Zeilenumbrüche, Überschriften, Formeln und Bildunterschriften lesbar bleiben.
3
Fahre mit der Vollkonvertierung fort, repariere die Quelle oder stoppe, bevor du mehr Aufwand in einen schlechten Scan steckst.
Woran Leser immer wieder scheitern
Auf Reddit, in Calibre-Threads und in E-Reader-Foren wiederholen Leser gescannter Bücher dieselben Frustrationen. Die Vorschau soll sie beantworten, bevor du vollständig konvertierst.
01
Viele gescannte PDFs sind nur Seitenfotos. Ohne brauchbare Textebene bleiben Konverter hängen, blähen die Datei auf oder betten jede Seite als Bild ein.
02
Versteckte OCR-Ebenen enthalten oft kaputte Trennungen, falsche Anführungszeichen, Störzeichen und Zeilenumbrüche, die in der Suche funktionieren, beim Reflow aber scheitern.
03
Wissenschaftliche Artikel und alte Zeitschriften verlieren schnell die Lesereihenfolge. Mehrspaltige Layouts, Formeln und Bildunterschriften sind die üblichen Bruchstellen.
04
Selbst wenn ein PDF geöffnet werden kann, wird Lesen auf kleinem Bildschirm oft zu Zoomen, Schieben, Zuschneiden, Wiederholen. Nutzer wollen vorher wissen, ob Reflow wirklich lesbar ist.
Diese Beispiele leisten mehr als Text: Sie zeigen, wie unterschiedliche gescannte PDFs vor der Konvertierung aussehen und was eine glaubwürdige EPUB-Vorschau erhalten muss.

Use Case 1
This is the simplest but highest-volume use case: judge whether a yellowed chapter scan becomes comfortable enough to read on a small e-reader.

Use Case 2
Formula pages break trust fast. A useful preview proves that equations, theorem blocks, and surrounding explanation still make sense on a real reading device.
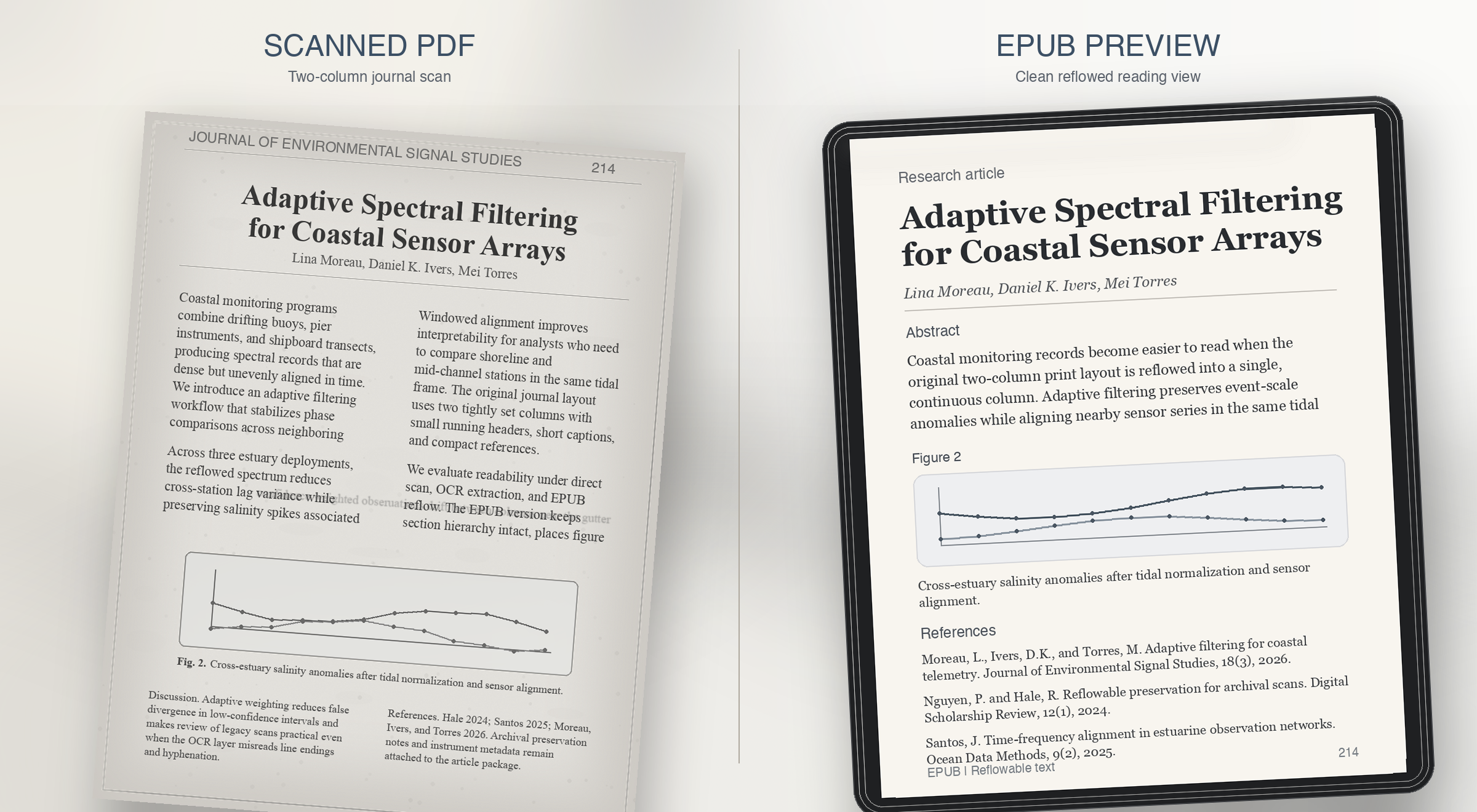
Use Case 3
Research journals usually fail on reading order. The preview should prove that columns, captions, and references survive reflow instead of collapsing together.

Use Case 4
Some PDFs have no usable text layer at all. The right behavior is not fake confidence, but a preview that shows what OCR recovered and what still needs review.
Simple pricing
Use the free preview to check OCR, reading order, and page-number leaks. Pro is for testing more PDFs. Done-for-you Repair is for files that need a human cleanup pass.
Free
$0 preview trial
Pro
$19 per month
Done-for-you Repair
from $199 per PDF
Pro checkout runs through Stripe after one-time email sign-in. If checkout is temporarily unavailable, the Pro button falls back to email. Repair work is still quoted from the preview report before delivery.
The live checker runs the repo's quality rules against extracted page text. It flags empty OCR output, page-number leaks, broken hyphenation, bad spacing, and formula-structure risk.
The current demo can generate a preview EPUB directly from an uploaded PDF. Production-grade full-book conversion still needs stronger layout recovery, better OCR repair, EPUB validation, and job orchestration.
In this demo, the PDF is uploaded to the current preview service so it can generate a sample EPUB. Review your deployment and privacy settings before testing private material. The page checker still exists for users who want to inspect extracted text before uploading.
The wedge is scanned PDF input, extracted page text for diagnosis, and a reflowable EPUB preview for reading on Kindle- and Kobo-style devices. It is not trying to become a broad everything-to-everything converter.
Accurate enough to judge reading comfort and obvious structural damage. The preview is meant to answer whether the book feels clean enough to continue, not to replace final editorial review for every edge case.
Some cleanup can be automated, but the product should stay honest about uncertainty. The key promise is to surface where review is needed so the user can decide whether to repair, crop, rerun OCR, or stop.
Those are the pages most likely to trigger risk labels. Formula structure, tabular alignment, footnotes, and badly cropped scans often need targeted repair before an EPUB is truly comfortable to read.
Readers and document owners with scanned books, academic PDFs, or public-domain material who want a reflowable EPUB for Kindle or Kobo without proofreading every page manually.
Generic converters export files, but they rarely explain where OCR or layout recovery failed. This product is designed to show risk before the user commits to a full conversion.
Yes. The main demo flow is designed around that exact question: upload one PDF, inspect the first pages, review OCR risk, and judge whether the full book is worth converting.
The most useful examples are before-and-after comparisons for noisy OCR, math-heavy academic pages, two-column journal layouts, footnotes, captions, and image-only scans that need OCR fallback.
It should prove reading comfort, not just file export. A good preview shows whether line breaks, page numbers, formulas, headings, columns, and captions still make sense on a small reading device.
Erhalte OCR-Notizen, EPUB-Vorschauen und Hinweise zur Vollkonvertierung.